
I build AI products that turn fragmented workflows into intelligent user experiences.
I design and build AI-powered tools, agents, and workflow systems across job search, interview preparation, and market intelligence — combining product thinking with engineering depth to solve real-world problems.
AI products and workflow systems I've built.
Each project below includes the problem it solves, what I built, core features, screenshots, and the stack used.
Interviewed
AI Job Discovery + Interview Prep Platform
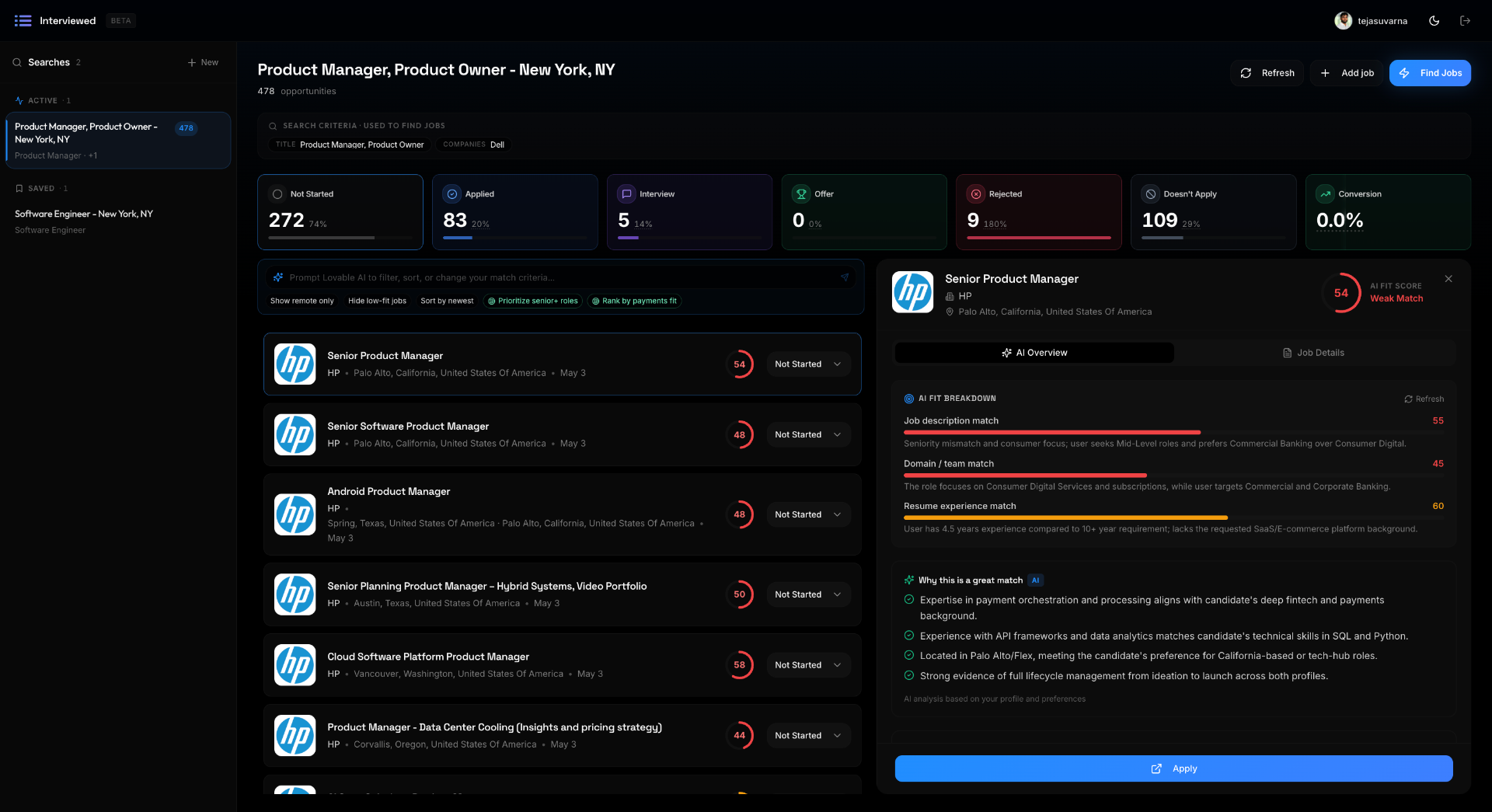
A serious job search lives across 8+ disconnected surfaces — LinkedIn, Greenhouse, Lever, Ashby, company pages, Gmail recruiter threads, Google Calendar, and a sprawl of Notion/Docs prep notes. Candidates lose hours every week re-reading JDs to judge fit, copy-pasting roles into trackers, hand-building question banks per company, and rewriting STAR stories from scratch. Generic prep content (Glassdoor, Reddit, ChatGPT one-shots) ignores the candidate's actual resume and the role's actual requirements, so prep quality scales linearly with effort and recall fades between rounds.
A single workspace that ingests the candidate's resume once, then continuously discovers roles across 20+ ATS sources, scores fit against the live profile, syncs interviews from Gmail and Google Calendar, and generates company- and round-specific prep packets on demand. A conversational layer replaces filter sidebars — 'Senior PM, fintech, remote-friendly, Series B+, no on-call' becomes a persistent saved search with daily new matches and explainable fit reasoning.
- •Conversational job search with persistent natural-language saved searches across 20+ ATS sources (Greenhouse, Lever, Ashby, Workday, etc.)
- •Resume parsing into structured skills, seniority, domain, and impact signals — re-used across every fit score and prep artifact
- •Per-role fit score (0–100) with line-item breakdown of matching skills, gaps, seniority delta, and domain overlap
- •Round-aware prep packets: likely behavioral questions, technical/system-design topics, recruiter screen talking points, and onsite logistics
- •STAR story generator that reuses parsed resume bullets and adapts them to the JD's competency rubric in real time
- •Gmail + Google Calendar sync that auto-detects interview invites, infers stage (recruiter screen → onsite → final), and links them to the tracked role
- •Company research dossiers: funding, recent news, exec moves, glassdoor red flags, and tailored questions to ask the interviewer
- •Application pipeline view with stage timeline, follow-up reminders, and outcome tracking for retro analysis
Briefly
AI News Research + Audio Briefing Workflow
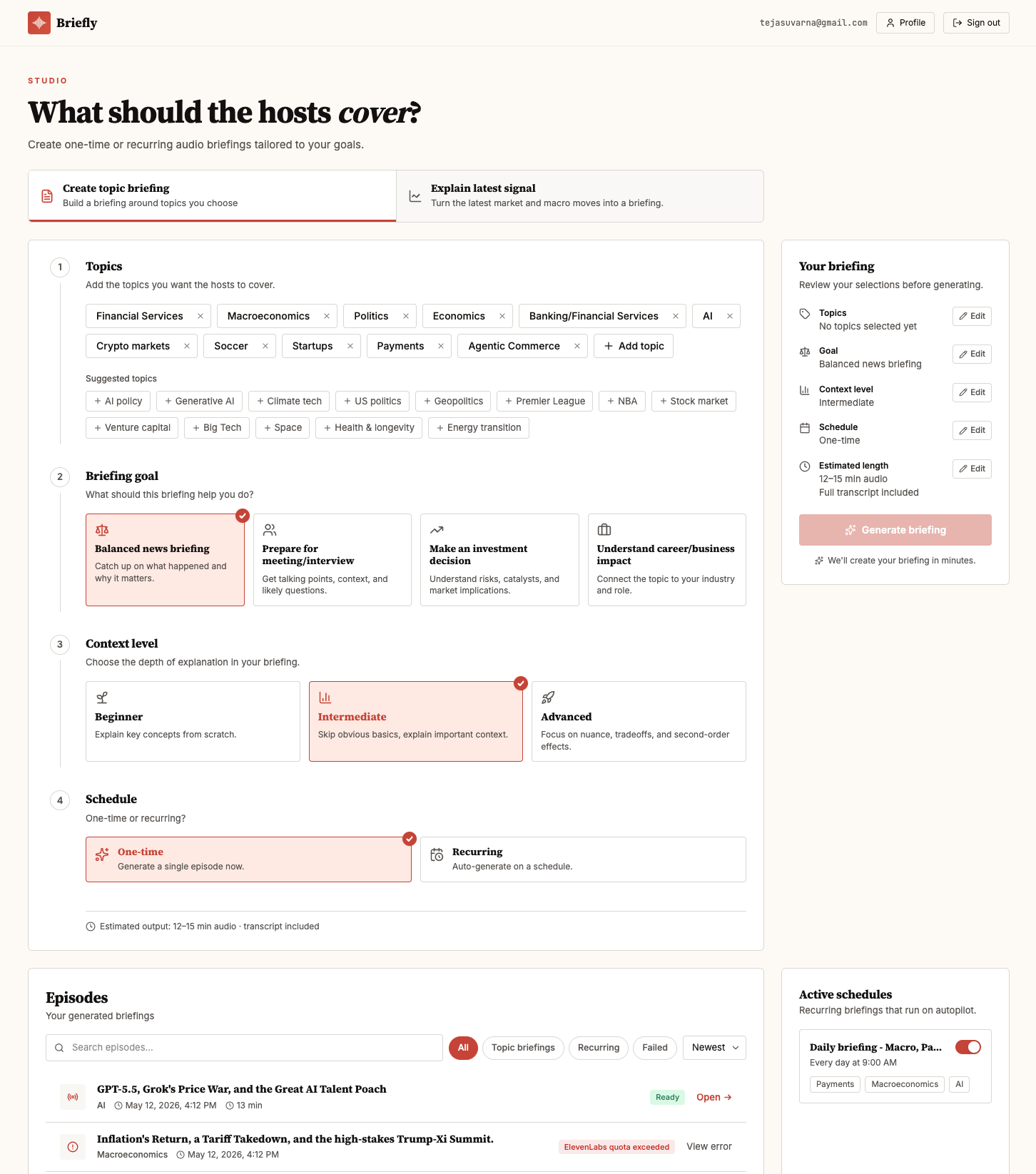

Anyone trying to stay current on macro, policy, technology, financial services, and crypto faces three real problems: (1) information sprawl across 30+ newsletters, podcasts, terminals, and Twitter lists; (2) summary fatigue — most digests are either headline-only (no 'so what') or 1500-word essays nobody reads before standup; and (3) zero personalization — the same Axios/Bloomberg blurb is sent to a derivatives PM, a fintech founder, and a retail investor, even though the implications are completely different for each.
A scheduled multi-agent workflow that, every morning, researches the last 24 hours of news across five tracked categories, ranks stories by materiality for a financial-services / long-term-investor lens, writes a narrative script (not a bullet dump), produces a 6–10 minute audio briefing in a consistent host voice, archives the script + audio + sources to Google Drive, and emails a stakeholder-ready summary with the audio attached. End-to-end hands-off — the operator just listens on the commute.
- •Scheduled daily run (cron-triggered) that pulls the previous 24h of coverage across politics, macro/economy, technology, financial services, and crypto
- •Per-category research agents using Perplexity Sonar + SerpAPI + Firecrawl to fetch primary sources, not aggregator rewrites
- •Story ranking pass that scores materiality (market impact, novelty, durability) and enforces category balance so no single topic dominates
- •Narrative script generation in a consistent editorial voice — intro, segment transitions, 'why it matters for FS/long-term investors,' and a sign-off
- •ElevenLabs TTS with a fixed host voice, normalized loudness, and chapter markers per segment
- •Google Drive archive auto-organized by date with the script (Doc), audio (MP3), and a sources sheet (Sheet) linked together
- •Gmail distribution with a scannable HTML summary, top 3 implications, audio attached, and links back to the Drive archive
- •Source citations preserved end-to-end — every claim in the script traces back to a URL in the sources sheet